

Google had a bunch of exciting announcements at its I/O developer conference this year.






Google had a bunch of exciting announcements at its I/O developer conference this year. Predictably, artificial intelligence played a big role in what the company had to show off, from a localized Assistant on your phone to a more powerful Google Lens.
However, the search giant also touched on some interesting points about how it’s making its AI better while still protecting your privacy. Machine learning models rely a lot on being fed data, but because they mostly come down to recognizing and interpreting patterns, it’s possible for bias to be introduced. Furthermore, some of the data being provided to these algorithms include how you use your device, so there are understandable concerns about how your information is being utilized.

HERE’S A LOOK AT THE TECHNOLOGIES GOOGLE IS EMPLOYING TO MITIGATE THESE CONCERNS. REMOVING BIAS
For all the wonders of AI, it’s far from perfect, and bias can be a problem when training a model. As we come to rely on AI to make decisions, it’s becoming increasingly important to understand how it arrived at a certain conclusion. Big players like IBM are already pushing for greater transparency in terms of how these algorithms work. There are also calls for “explainable” AI, which is basically AI that is designed to be transparent and interpretable from the outset. This is super important in terms of accountability, especially when you task AI with important systems like those in a self-driving car.
It’s still a popular opinion that deep neural networks are virtual mystery boxes with inscrutable workings, but Google is trying to change that with a technique called TCAV. Short for Testing with Concept Activation Vectors, TCAV works by letting developers inspect their algorithms and see the concepts that the AI is associating with their samples.
Take image recognition for example. Many machine learning algorithms operate using low-level features such as edges and colors in individual pixels, which is a far cry from how humans process images. TCAV operates at a higher level with big picture concepts, so humans can actually comprehend it. For instance, a model that is trained to detect pictures of doctors could mistakenly assume that being male was an important characteristic because the training data included more images of men. With TCAV, researchers could identify this bias in their models and correct for it.
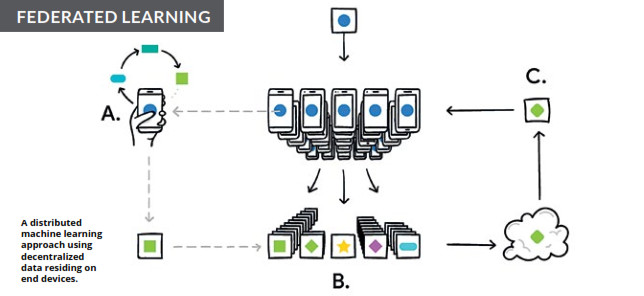
TRAINING AI WHILE KEEPING YOUR DATA SAFE
One of the biggest issues with training AI is the amount of data it needs to become effective. Inevitably, this means concerns about data sharing and what’s happening to your information as it bounces around the brain of some virtual intelligence in the cloud. Google thinks it has a possible solution to this with federated learning, a new technique that lets scientists train AI models without raw data ever leaving your device.
In the case of smartphones, it allows devices to collaboratively learn a shared prediction model while keeping all the training data on the device itself, effectively decoupling an algorithm’s training from the need to store data in the cloud. This is different from simply having a local model on your phone, and it goes a step further because the training is happening on your device as well.
Google’s Gboard keyboard can learn a new word like “Targaryen” or “BTS”, without it knowing what you’re typing at all. Because so many people have typed the word, the shared prediction model has been updated to refiect that. Your device basically downloads the current model, lets it learn from data on your phone, and then summarizes the changes as a small, focused update. It is this update, and not your data, that is then encrypted and sent to the cloud, where it is averaged with other user updates in order to improve the shared model. This means that there are no identifying tags or individual updates in the cloud, and all the training data stays on your phone.
That said, there have been big hurdles to overcome. For example, training can’t happen all the time, and on device training requires a mini version of TensorFlow, in addition to careful scheduling to ensure training only happens when the device is idle, plugged in, and on a free wireless connection. But with the right implementation, federated learning can be immensely useful, enabling smarter models, lower latency, and lower power consumption, while at the same time ensuring privacy.

ILLUSTRATIONS GOOGLE
PICTURE 123RF














